A quick way to find duplicate and similar files is necessary to keep a clean and clear map structure on your hard drive across the shared network storage.
To find duplicate files with XYPlorer we use the find files feature. Open it by pressing Ctrl+F then go to the Dupes tab to search for duplicate and similar files.
Let's jump in to learn how we can use this feature in detail

Let's start by explaining how the find files interface works. If you are here, simply to find duplicates by name or by exact content match, continue reading below for the step-by-step instructions for that.
Now, to open the find files interface start by pressing Ctrl+F or go to edit->Find files to open the find files interface.
We can also open this interface by pressing F12 or the blue up arrow icon in the bottom right corner of the interface and then choose find files if it opens to another tab.
In the find files interface we will see two rows of tabs while we are in the find files tab in the first row. All tabs in the second row belong to the find files interface. So, in the second row, you should see these:
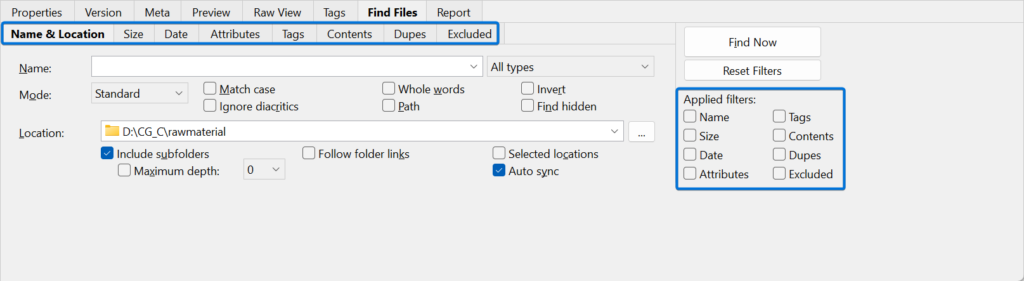
You can see the tabs also represented in a two-column list on the right side with a checkbox next to each. A checkbox next to one of these names indicates that the settings in that tab are applied to the current find filter.
If we head over to the Dupes tab where we have settings for duplicates, you will find that we cannot write anything here, instead we can only filter by predefined types of data. For example, by name, by content, date, or size as well as image.
To specify what name or size we want to search for we have to go to the respective tab and fill data in there.
You could say that we use all tabs to first filter out what we want to look for and then we use the dupes tab to say that we only want to zoom in on duplicates within the range of files we filtered down to in the other tabs.
Sometimes we simply need to find files by name. For example, we might have a project folder with 10 different projects, each in a separate subfolder. For each project we might have a log file that all share the same name. If we want to collect all of them, we can do so by finding duplicates by name even if they don't have the exact same contents.
To find duplicate files or folders by name follow these steps:
Press Ctrl+F or go to edit->Find files to open the find files interface.
Next go to the name and location tab. Select a location. The easiest is to simply select a location in your tree view. You can also type, or copy paste the path into the location field. You can also press the three dots icon just next to the field to browse for your location.
This will narrow down the search so that it doesn't take too long to search. Just keep in mind that if one of your duplicates is in another location, they won't be matched as duplicates. Both files need to be located within the path.
So, if your path is C:\projects\project1 and you want to find duplicates among all your projects you need to search c:\projects instead.
Next, type the name of the file you are trying to find duplicates for. If you just want to find all duplicates of any kind within the specified folder, leave the name filed blank.
Next, go to the dupes tab and check Name. You can also choose if the extension should be the same, different or to be ignored.
Now, check the name and dupes checkboxes in the applied filters just below the "find now" and "reset filters" buttons.
Depending on how much data you search, the time it takes can vary greatly.
Your search will pop up as a new tab in your current active list view.
To find exact file copies including the contents of it. For example, two text files with exactly the same data inside or two excel files that are copies of each other we can use the content checkbox in the dupes tab while in the find files interface.
By not also looking for names duplicates we can even find files that have the same content even if they have different names.
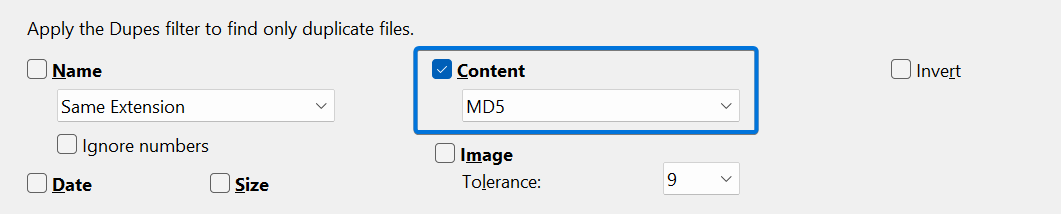
Below the content checkbox there is also a dropdown, by default set to MD5. There are also various SHA alternatives as well as byte-to-byte. These are different methods to verify that the contents of a file indeed are the same or not.
For me I usually stick to MD5. MD5 will generate a unique fingerprint for each file and match them to each other. This is much faster than something like byte-to-byte where every little pices of a file has to be checked for a match.
So in short, here are the steps:
For finding images that are similar the process is slightly different than finding duplicate content of other file types.
In the dupes tab found in the find files interface we have an image checkbox with a tolerance value.

The tolerance value is how much two images can differ before they are not considered duplicates. For example we might have multiple versions of the same image that we are trying to find. Perhaps one light weight for web, one for print and a couple of resolutions in between.
In this case we can tune the tolerance value so that these variations can fall into the same bucket and be considered duplicates.
Here are the steps:
In this article we looked at how we can search for and find duplicate files based on various conditions.
We started with the basic interface and how it is structured. Then we looked at three examples. The first example was a match by file name, then we went ahead and looked at an example where we looked for files with duplicate content.
Last we looked at how we can narrow down a find duplicate search to find similar but not exactly the same images using XYplorer
I hope this was helpful and thanks for your time.
